用 Python 写了一个抓取 JSON 接口数据的框架(我的第一个 Python 作品,因为没有链接跟随功能所以我就不好意思叫它爬虫了,不过嘛算是都是爬虫的基本组成部分 ![]() )。
)。
主要用于扒取以固定 JSON 格式返回变化结果的 API 接口数据,代表是各类一言接口 ![]() ,抓取下来的数据将储存在 Microsoft Access 数据库中(accdb 格式数据库),不要问我为什么用 Access
,抓取下来的数据将储存在 Microsoft Access 数据库中(accdb 格式数据库),不要问我为什么用 Access ![]()
带有匹配功能,自动检测是否已经存在相同数据,如存在则不会重复写入。
使用请安装 import 所列出来的依赖,确保已经安装了 Microsoft Access 以及相应的驱动,我开发的环境是 Windows 10 + Microsoft Office Access 2016 + Python 3.6 (64-bit)。
默认抓取的 JSON 字段是 text、source、catname,数据库结构如下图,都是按照我扒取的 API 写的,可针对自己的情况修改、增加、删除字段,注意共 4 处 SQL 查询语句以及相应的写入语句都需要做出调整。
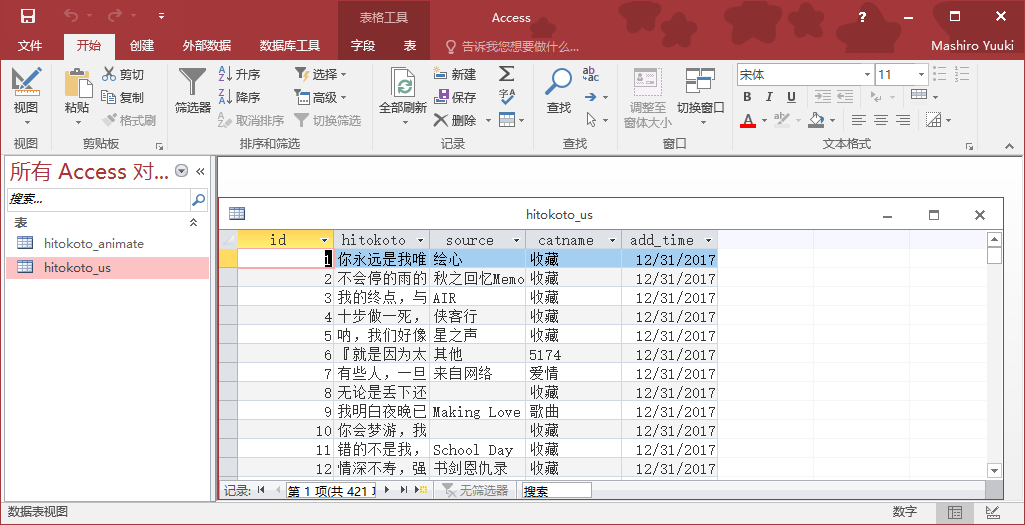
注意:
1. 不要多线程跑,可能导致数据库 id 重复!
2. 因为中途遇到部分数据错误可能导致程序被终止,所以使用 try except pass 来规避错误,因此带来的后果是 Ctrl+C 无法终止进程,只能关闭窗口或者通过 PID 结束进程。如果有好的解决办法请指点。
参数设置说明:
url = "https://example.com" # 爬取的接口 url,我不会告诉你我是用来扒谁的哈哈 loop_times = 200000 # 设置抓取次数,当然越多匹配效果越好,假设检验一下就知道了 sleep_time = False # 每次抓取是否需要间隔(防止抓取过快被 ban) # 下面填你的数据库文件路径,只接受 accdb 格式! db_location = "c:\\WorkDirectory\GitHub\py-wd\crawler_v1.0\hitokoto.accdb" remove_old_db = False # 是否删除旧数据库文件,请却保无重要数据 create_new_db = False # 是否创建新数据库? table_name = "hitokoto_us" # 准备写入的 TABLE 名称 create_new_table = False # 是否创建新 TABLE(将使用上面的名称)? is_first_time = False # 是否是第一次在这张 TABLE 内写入数据?
以下是源码:
import requests import pypyodbc import json import time import random import os ############## # Parameters # ############## url = "https://example.com" loop_times = 200000 # Set times of loops sleep_time = False # Do you need a sleep between two requests? # Your database location, MS Access Database ONLY! db_location = "c:\\WorkDirectory\GitHub\py-wd\crawler_v1.0\hitokoto.accdb" remove_old_db = False # Do you want to remove the old database file? Make sure that contains nothing important! create_new_db = False # Do you want to create a new database? table_name = "hitokoto_us" # The table you are going to write! create_new_table = False # Do you want to create a new table (with the name above)? is_first_time = False # Is it the first time to write in this table? ############## # Create table def Create_Table(): SQL = 'CREATE TABLE ' + table_name +' (id int,hitokoto varchar(255),source varchar(255),add_time DateTime)' conn.cursor().execute(SQL) cur.commit() def Request_Job(index): response = requests.get(url) #print (response.text) data = response.json() print ('Writing id = ' + str(index)) print (data['text']) print (data['source']) print (data['catname']) # Write hitokoto_query = "\'" + data['text'] + "\'" hitokoto_query.replace("'", '\'') hitokoto_query.replace("''", '\"') data['text'].replace("\'\'", '') # Fix a Speciall bug... is_new = Check_Dup(hitokoto_query) if is_new: Write_DB(data,index) # Time sleep if sleep_time: timer = random.randint(0,3) time.sleep(timer/10) # Insert Data def Write_DB(data,index): localtime = time.strftime("%Y-%m-%d", time.localtime()) sql_insert = '''INSERT INTO ''' + table_name + '''(id,hitokoto,source,catname,add_time) VALUES(?,?,?,?,?)''' insert_value = (index, data['text'], data['source'], data['catname'], localtime) cur.execute(sql_insert, insert_value) cur.commit() # Check duplicate or not def Check_Dup(check_hitokoto): SQL_query = '''SELECT * FROM ''' + table_name + ''' WHERE `hitokoto` = ''' + check_hitokoto cur.execute(SQL_query) row = cur.fetchone() if row: print ('Nothing Speciall!') return False else: print ('This is New!') return True ############## # Main Start # ############## # Remove old accdb if remove_old_db: os.remove(db_location) # Creat new database if create_new_db: connection = pypyodbc.win_create_mdb(db_location) # Connect to accdb connStr = 'Driver={Microsoft Access Driver (*.mdb)};DBQ=' + db_location conn = pypyodbc.win_connect_mdb(connStr) # Create a cursor cur = conn.cursor() # Creater a TABLE if create_new_table: Create_Table() if is_first_time: Request_Job(1) # For the first time. Must comment this line in the second time! Important! # Requests Start print ('Begin!') for x in range(1, loop_times): try: SQL_max_id = 'SELECT MAX(id) FROM ' + table_name cur.execute(SQL_max_id) max_id = cur.fetchone()[0] Request_Job(max_id + 1) print ("Info: Job Finished!") except: # Handeling Exceptions print ("Error: Operating Failed!") pass else: print ("Succeed") times = round(x*(50/loop_times)) print (u"\u2588" * times + u"\u2592" * (50-times)) print ('All Done!')
可以在 GitHub Gist 上查看,需科学上网。
Q.E.D.





